揭秘阿里IT運維的基礎設施,詳細分析是如何支持百萬級規模服務器管控?
簡介:還記得這些年我們晚上爬起來重啟服務器的黑歷史嗎?雙十一期間,阿里巴巴是如何安全、穩定、高效、順暢地管理數百萬主機的?阿里巴巴運維中心技術專家宋毅首次解密阿里巴巴IT運維的基礎設施,詳細分析了如何支撐百萬級規模服務器的管控?如何像生活中的水原煤一樣做好阿里巴巴運維的基礎設施平臺?
客人介紹
宋健(Song Yi):阿里巴巴運維中臺技術專家。經過10年的工作,他依然專注于運維領??域,對大型運維系統和自動化運維有著深刻的理解和實踐。 2010年加入阿里巴巴,目前負責基礎運維平臺。加入阿里后負責:從零開始搭建支付寶基礎監控系統,推進全集團監控系統整合一、運維工具&測試PE團隊。
從云效應來看2.0智能運維平臺(簡稱:)產品,運維可以定義為兩個平臺,基礎運維平臺和應用運維平臺。基礎運維平臺是統一的,稱為,不愧是阿里巴巴IT運維的基礎設施。
從10000臺服務器到臺服務器,再到數百萬臺服務器,基礎設施的重要性并不是一開始就意識到的,而是逐漸被發現的。無論是運維系統的穩定性、性能還是容量,早已無法滿足服務器數量和業務的快速下滑。 2015年我們升級架構,系統成功率從90%提升到99.995%,單日調用量也從1000萬提升到1億多。
全球擁有百萬級服務器規模的公司屈指可數。然而,許多公司已經被業務拆分。每個企業管理自己的服務器,一個系統管理數百萬臺機器。應該少一些,所以我們沒有太多可以學習的東西。在大多數情況下,我們都在以自己的方式前進,我們的系統也在這個過程中演變成今天的樣子。
產品介紹
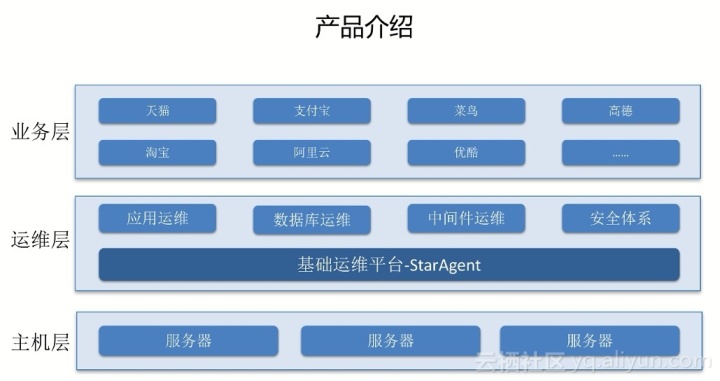
如上圖,分為三層:主機層、運維層、業務層。每個團隊根據分層方法進行合作。通過這張圖,可以大致了解產品在組內的位置,是組內唯一的一個。官方默認代理。
應用場景
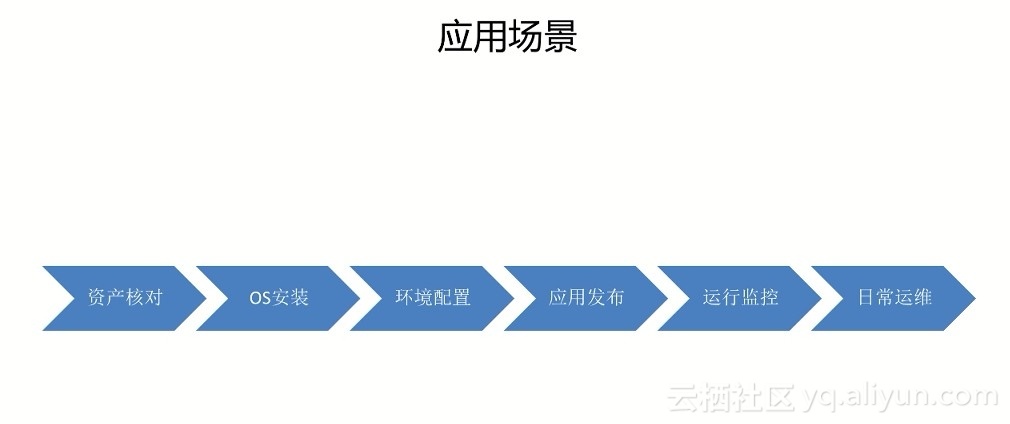
貫穿整個服務器生命周期:
產品數據

這也是我們在阿里產品的一些數據。每天晚上有上億臺服務器操作,1分鐘可以操作50萬臺服務器,有150多個插件,管理服務器規模在百萬級,Agent資源占用率也很低支持 Linux/主流發行版。
產品特點
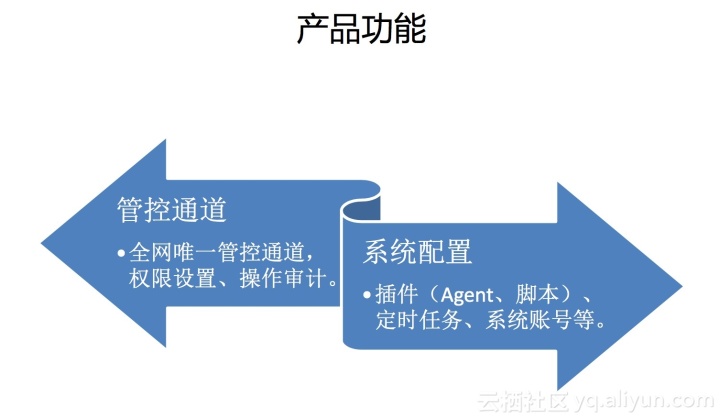
核心功能可以概括為兩大部分:控制通道和系統配置。這個和開源的//和其他配置管理產品差不多,我們做的更精細一點。

按照API、Agent細分的功能列表主要供一線開發運維朋友使用。 API 多用于底層運維系統調用。 Agent代表了可以在每臺機器上直接使用的能力。
API
代理
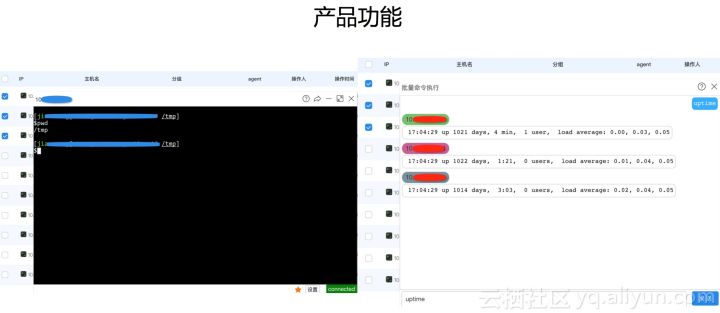
圖:左邊是web終端,手動發信號,可以以JS的形式嵌入到任何網頁中。左邊是批量執行命令的功能。首先選擇一批機器,在這個頁面輸入的命令會發送到這批機器上。系統架構
邏輯架構
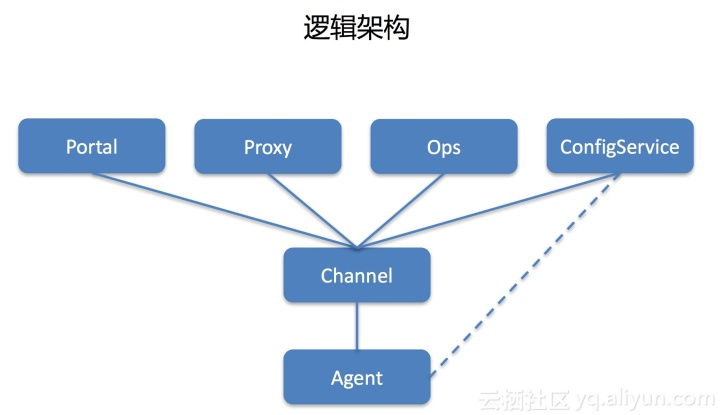
我們的系統是三層架構。每臺機器安裝代理,完善長連接。之后,連接代理的信息會定期上報給中心,中心會維護完整的代理和關系數據。共享兩個進程:
1.代理注冊
代理有一個默認配置文件。啟動后,它首先連接。連接時會上報本機IP、SN等必要信息。它估計應該連接到哪個集群,并將其返回到列表中。然后和它建立一個長連接。
2.發送命令
外部系統調用代理發出命令。 proxy收到請求后,會根據目標機器找出對應關系,然后下發任務給agent,再把命令轉發給agent執行。
部署框架
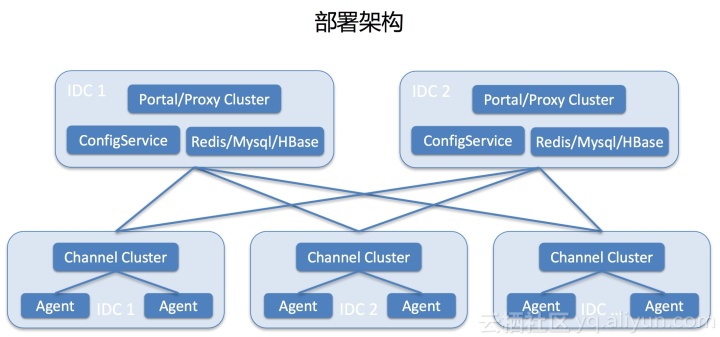
最底層是每個IDC,每個IDC會部署一個集群服務器運維技術,Agent會在其中一個隨機建立一個長連接。里面是中心。中心部署了兩個機房進行容災,同時在線提供服務。其中一間機房的死亡不會影響業務。
問題與挑戰
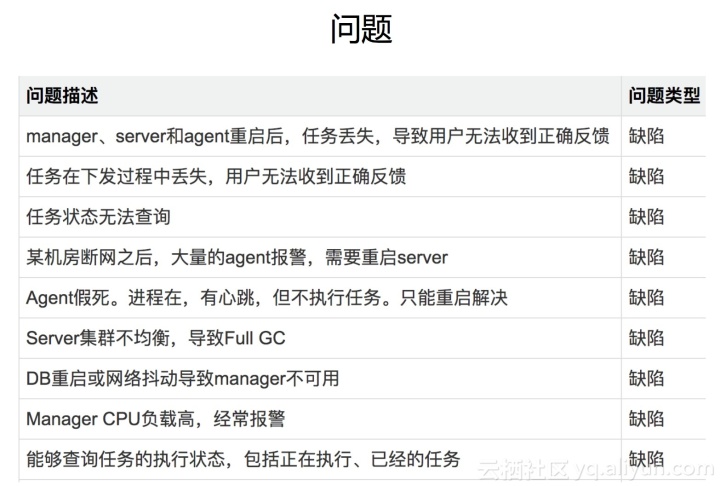
如上圖:是前年在系統建設中遇到的問題:
前三個問題有點類似,主要是任務是狀態引起的。 1.0 可以理解為 2.0 中的代理,相當于一直有大量系統在線 發出命令時,如果重啟 //agent 的任何角色在 1.0 中,此鏈接上的任務將失敗。比如連接到它的agent重啟后會斷開連接,因為鏈條斷了,當時這個站下達的命令是拿不到結果的。重啟會導致負載不均的第六個問題。假設一個IDC有10000臺機器,兩臺機器分別連接5000臺機器。重啟后,10000臺機器全部連接到一臺機器上。
如果用戶調用API發出命令失敗,他們會過來讓我們檢查原因。有時候確實是系統問題,但是也有很多環境問題,比如機器宕機、SSH失敗、負載過高等等。當磁盤滿了等等,百萬級的服務器有10000臺機器,而每晚有百分之一的機器。回答問題的數量可想而知。那個時候,我們很郁悶。每天晚上有一半的團隊成員在回答問題。晚上有一次斷網演習,我們只好爬起來重啟服務恢復。
如何解決這個問題?我們將問題分為兩類:系統問題和環境問題。

系統問題
我們已經對系統進行了徹底的構建,采用分布式消息架構,或者以發送如下命令為例,每次都是一個任務,每個任務的狀態在2.0 , 代理收到發出命令的請求后,會先記錄并設置接收任務的狀態,然后發送給代理。代理收到任務后,會立即響應。代理收到代理的響應后,將狀態設置為執行期間,代理在執行完成后主動上報結果,代理收到結果后將狀態設置為執行完成。
整個過程中proxy和agent之間的消息都有確認機制,重試會在不確認的情況下進行。這樣,如果重啟了任務執行過程中涉及的角色,對任務本身不會有太大影響。
2.0 集群中的機器會相互通信服務器運維技術,定期上報連接的agent數量等信息,并將接收到的信息與自己的信息結合起來。如果連接的agent太多,會手動斷開最近沒有任務執行的機器,通過這種方式解決負載均衡問題。中心節點與所有節點有長期連接,并存儲每個連接的代理數量。當發現某個機房出現異常或容量過高時,會手動觸發擴容或臨時借用其他機房。擴展將被手動移除。
環境問題
在2.0中,每一層proxy//agent都有詳細的錯誤碼。通過錯誤碼,可以直觀的判斷出任務錯誤的原因。
對于機器本身的問題,連接監控系統中的數據。任務失敗后會觸發環境檢測,包括宕機時間、磁盤空間、負載等,如果有相應問題,API會直接返回本機。數據負責人也返回,讓用戶看結果就知道原因和處理誰。同時,這些診斷能力會以釘釘機器人的形式開放,讓你平時可以直接在群@機器人做測試和確認。

穩定
從上面的介紹可以看出,我們可能是運維的基礎設施。就像生活中的水、電和煤一樣,您所有的服務器運營都非常依賴我們。當我們出現故障時,如果線上業務也出現嚴重故障,那么業務故障只能等待。由于服務器無法操作,無法發布和更改,因此對系統穩定性的要求非常高。在同城雙機房、異地多中心容災部署中,依賴的存儲是mysql/redis/hbase,而這個存儲本身就有高可用保障。單個存儲故障不會影響業務,相信業內很少有系統能達到這個水平。
安全
1分鐘可以操作50萬臺服務器,輸入命令回車瞬間可以操作上萬臺機器。如果是惡意破壞性操作,其影響可想而知。因此實現了攔截高危指令的功能,對一些高危操作進行人工識別和攔截。整個調用鏈也經過加密和簽名,確保第三方難以破解或篡改。針對API賬號可能泄露的問題,還開發了命令映射功能,通過映射改變操作系統中的命令。例如,要執行命令,可能需要傳入 a1b2。每個API賬號的映射關系都不一樣。
環境
連接監控數據可以解決機器停機等環境問題。前面說了,網絡隔離的問題就不過多討論了。這里我們重點關注CMDB中錄入的數據與Agent采集的數據不一致的問題,主要是SN、IP等基礎信息,因為你在使用的時候,首先從CMDB中提取機器信息,而然后調用我們的系統。如果不一致會直接導致調用失敗,為什么會出現SN/IP不一致的問題?
CMDB 中的數據通常是由手動或其他系統觸發和輸入的,而 Agent 實際上是從機器上收集的。有的機器顯卡上沒有SN編程,有的機器網卡很多等等,環境比較復雜,各種情況都有。
這些情況都是通過構建規范來解決的,分別制定SN和IP采集規范,允許在機器上自定義機器的SN/IP,并提供采集工具配合規范。除了我們的Agent,其他所有機器信息都被收集了這個收集工具可以在所有場景中使用。當規范更新時,我們會同步更新,實現對底層業務的透明化。
原創
更多技術干貨,請關注云棲社區知乎組織號:阿里云云棲社區-知乎

 售前咨詢專員
售前咨詢專員
